Add Git Ignore to an existing Visual Studio Solution (New Git Experience)
A few years ago I wrote a post covering how to Add Git Ignore to an existing Visual Studio Project which was using Visual Studio 2015 I believe. Though it is an old post, it holds up through the current version of Visual Studio. Fast forward to today and Visual Studio has a new Git Experience in preview which alters this process. This post will cover adding a Git ignore file to an existing solution using Visual Studio’s new Git experience. If you don’t see the Git menu in Visual Studio see the previous link for information on enabling the feature preview.

Using Visual Studio to add a .gitignore
Open Visual Studio and the solution needing an ignore file. From the top menu select Git > Settings.

The above will open Visual Studio’s Options with Source Control > Git Global Settings selected. From the list on the left select Git Repository Settings and then click the Add button for Ignore file.
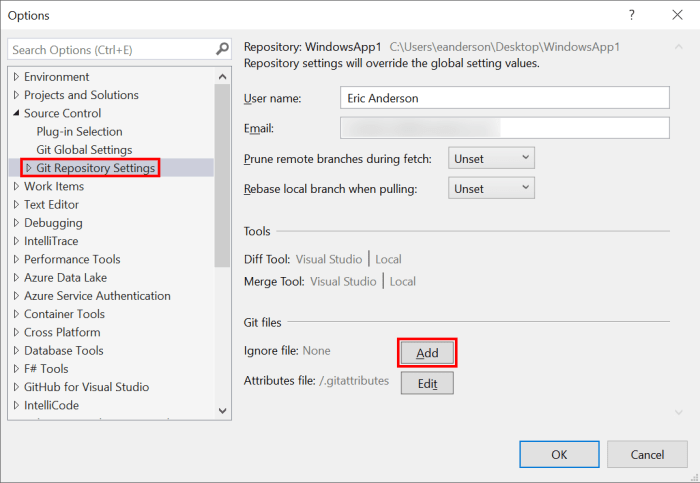
The above will add a .gitignore file with all the proper files ignored for a typical Visual Studio setup. Switch to the Git Changes window and enter a commit message and then click the Commit Staged button to commit the change to your current working branch.

Stop tracking files that should be ignored
To stop tracking the files in the ignore file open a command prompt and navigate to the directory that contains your solution file (.sln) and run the following commands.
git rm -r --cached . git add . git commit -am "Remove ignored files"
The Git commands above were pulled from here. There are other answers in that thread if the above doesn’t work on your project for some reason.
Wrapping Up
It is always simpler if you can start a project with a Git ignore file in place, but if for whatever reason that couldn’t happen hopefully this post will get you going. If you aren’t using the new Visual Studio Git experience then the original version of this post will be more helpful. Check out the Microsoft post for more details on the new Git experience.
Add Git Ignore to an existing Visual Studio Solution (New Git Experience) Read More »




















